Milan
Liessens Dujardin
Machine Learning Engineer • Music/AI & Design Researcher • Musician


I'm passionate about the intersection of music, machine learning, human simulation, design interfaces, and human-AI co-creation. My current work focuses on post-training ALMs for musical understanding and reasoning, and controlling audio effects from natural language for music post-production. I am also doing research on simulating user behavior for UI testing, as well as how LLMs can help designers reach better design outcomes through supported ideation following the C-K Design Theory. My background spans from commercializing cutting-edge technologies at Lawrence Berkeley National Laboratory to machine learning engineering and research in music & AI. Currently, I am pursuing my M.Eng. in Electrical Engineering and Computer Science at UC Berkeley..
Focus on machine learning, natural language processing, music-AI, and human-AI interaction.
Developed commercialization strategies to bring innovative technologies from Lawrence Berkeley National Laboratory to market.
This project focused on bridging the gap between cutting-edge research in high-performance computing from Lawrence Berkeley National Laboratory and commercial applications. I conducted extensive market research, patent analysis, and competitive landscape assessments to identify opportunities for superconducting, neuromorphic computers.

Collaborators: Ayushman Dey, Laia Coronas Sala, Jasper Ryan, Jeremy Vale, and Mitchell Lee.
A collaborative design reasoning system inspired by C-K Theory and Git workflows, supporting structured AI-assisted ideation.
This project explores how artificial intelligence can support collaborative design within functions and areas of engineering and design during the early stages of innovation. While large language models (LLMs) are effective at generating ideas, most current AI tools function as isolated conversational systems that do not preserve reasoning, connect ideas to supporting knowledge, or support collaboration between multiple contributors.
To address this gap, we developed C-K Git, a collaborative design reasoning system inspired by Concept–Knowledge (C-K) Theory and version-control workflows such as Git. C-K Theory distinguishes between concept space, which contains emerging and uncertain ideas, and knowledge space, which contains validated information and assumptions. Design progresses through interaction between these spaces, allowing ideas to evolve through reasoning and refinement.
C-K Git provides a structured workspace where users can explore concepts, connect them to knowledge, and collaborate through branching and merging workflows. Designers can independently develop ideas and later merge their work into a shared concept space while preserving ownership and reasoning history. Rather than replacing human creativity, the system supports transparent collaboration by making design reasoning visible and traceable within product, user experience, or engineering design.
Music Notation for Language Models — a time-grounded representation enabling fine-grained music understanding in audio-language models.
Music understanding from audio requires jointly perceiving what is played (content) and how it is played (performance), grounded in time. Yet existing audio-language model training pipelines rely on LLM-synthesized captions and metadata that are typically coarse and weakly time-grounded, limiting their ability to capture fine-grained musical content and performance detail.
We introduce MuNo-LM (Music Notation for Language Models), a text-based representation that unifies score-level information — harmony, phrasing, dynamics, voicing, articulation — with time-aligned audio-perceptual features, in a format that is both expressive and directly comprehensible by LLMs. Building on this representation, we propose an automatic caption generation pipeline that translates aligned score-performance data into time-grounded and musically informed auditory analyses and question-answer pairs. We assess output quality and temporal grounding via inter-annotator agreement, confirming that MuNo-LM QA pairs constitute reliable supervision, paving the way to fine-grained music understanding in ALMs.
A systematic evaluation suite measuring pitch hearing in audio-language models across instruments, acoustic conditions, and response formats.
Audio-language models (ALMs) are increasingly used in real-world applications that require understanding music — from music tutoring and transcription to captioning, recommendation systems, and music production. This makes reliable musical perception a critical prerequisite: if a model cannot accurately hear the structure of sound, it cannot be trusted to reason about, teach, transcribe, or act on audio in the real world. Yet existing benchmarks rarely assess one of the most fundamental musical abilities underlying such perception: pitch hearing.
We introduce PitchBench, an evaluation suite that systematically measures pitch hearing in ALMs. PitchBench comprises 28 experiments spanning absolute and relative pitch perception within sequences and chords, while varying loudness, note duration, sound source, time stretching, background noise, and other acoustic conditions. Tasks range from identifying individual pitches in isolation to tracking a melodic line within a four-part musical texture.
Evaluating frontier ALMs, we find that pitch hearing remains highly unreliable: models perform consistently poorly across settings, with accuracy varying sharply by sound source, note duration, and notation format. Current ALMs do not yet possess stable pitch perception, even for controlled synthetic and instrumental stimuli. Alongside the benchmark, we release PitchBench as a Python package containing the evaluation data and data generation tools to support future work on pitch-aware audio-language modeling.
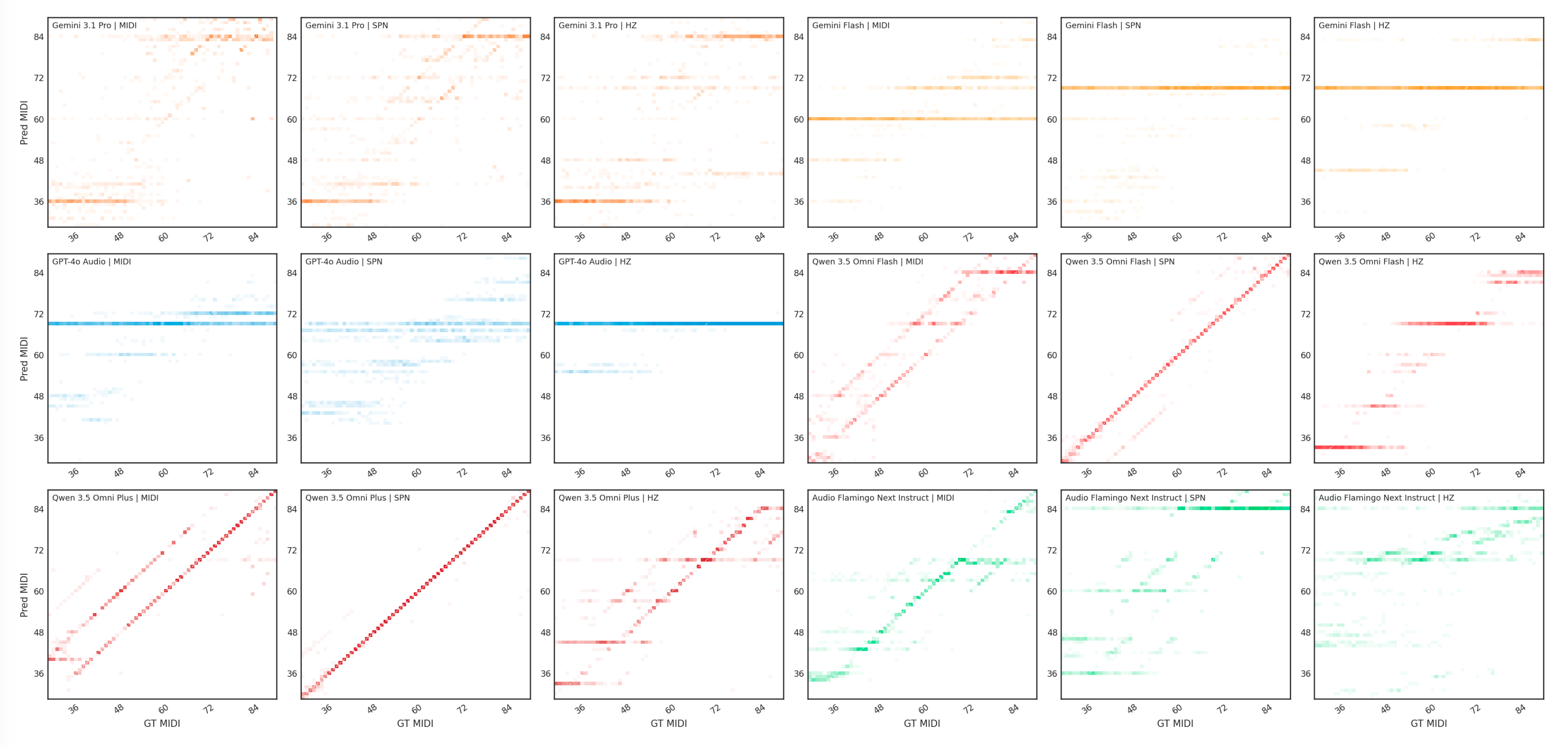
The confusion matrix above illustrates the performance of frontier ALMs on pitch perception (experiment A1). In this controlled setting (unprocessed 5-second pitch only at the beginning of the audio clip), some models perform well (90% accuracy), whereas others struggle to consistently identify pitches.
Multi-turn, text-guided audio effect refinement via a hybrid LLM and CLAP-optimization architecture.
Existing text-to-preset systems are largely single-shot: given one textual descriptor, they generate one preset. Real audio engineering, however, is sequential — engineers iteratively refine an existing effect chain through successive instructions. This setting raises a stateful problem: given the current parameter state and a sequence of instructions, how can a system update the sound while preserving and refining the current state?
InstructFX2FX addresses this problem with a hybrid language-model and CLAP-optimization architecture. An LLM acts as a high-level planner, selecting effects, ordering the signal chain, and proposing initial parameters — motivated by recent evidence that LLM-based initialization outperforms CLAP optimization from random initialization. CLAP-guided optimization then refines those parameters perceptually, providing a more stable and reproducible refinement mechanism than LLM-only reprompting.
An email client with AI-powered features to help users manage and respond to their emails more efficiently.
Existing email clients are often inefficient and just don't have the features users (I) want. This project aims to turn exasperating-MAIL into epic-MAIL (the real reason why they put an 'e' in front of 'mail').
I sometimes improvise or compose. I have also collaborated with talented artists doing cool stuff.
This piece was created using sounds from a modular synthesizer and was edited in Logic Pro X.
A peek inside the donkey's mind.
An improvisation in 7/8.
'Stripped' was created in collaboration with Zita de Aguirre y Otegui, Illa De Preter, and Adrián Henríquez.
Automated Disaster Assessment from Satellite Imagery.
We present a systematic analytical framework for classifying disaster types and assessing damage levels in satellite imagery under severe data scarcity and extreme class imbalance. Our methodology extracts signal from noisy, limited data through three interdependent components: (1) structure-preserving artifact correction (mirroring-based occlusion handling) that outperforms naive imputation and generalizes across model families; (2) exploratory data analysis guiding feature engineering to identify generalizable discriminative features based on color distributions and structural patterns; and (3) task-aware model selection comparing classical and deep learning approaches under realistic constraints.
A low-friction, intelligent meal and workout tracking application.
Vibe-coded a prototype for SUMIRE, an app designed to simplify meal and workout tracking using AI. Conducted 4 extensive customer discovery interviews to validate/reject my hypotheses and refine the product concept and features. My prototype is under construction here. Feel free to try it out: just upload a photo of your meal. SUMIRE means violet in Japanese.
Key findings from interviews and the product discovery process include (1) Looking for a problem to the solution limits thinking outside the box. (2) Product discovery is about finding commonalities in what people image the product to be. (3) Fast logging attracts users; accuracy and comprehensiveness retain users. (4) Fundamentally, users want to establish a lasting, healthy relationship with food and exercise.